Imagine a world where every piece of digital information—every tweet, transaction, and temperature reading—could be processed and analyzed almost instantly, no matter the scale. This isn't just a dream scenario for data scientists and IT professionals; it's becoming a daily reality thanks to the advancements in large-scale data stores operating in distributed computing environments.
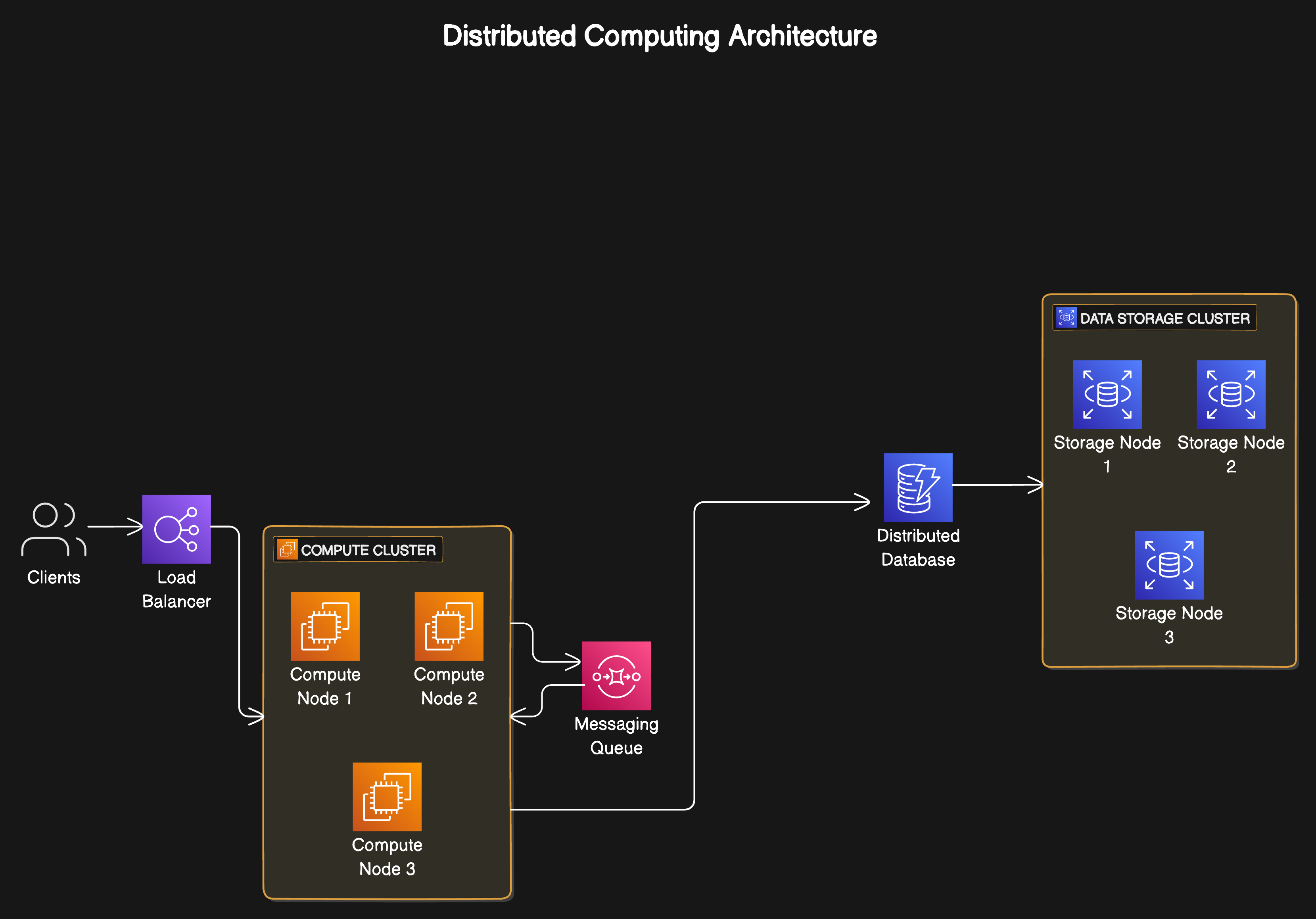
In the realm of big data, the challenge isn't just collecting information but managing, processing, and extracting value from it across multiple, often globally dispersed, computing resources. Distributed computing addresses these challenges by dispersing data workloads across many servers, enhancing both performance and fault tolerance.
In this blog, we take a look into the operation of big data stores, predominantly with a focus on Apache Hive and Apache Cassandra. These are classic examples of integrating principles of distributed computing with state-of-the-art data management techniques to offer scalable, reliable, and efficient solutions. We will take a deeper dive into how these data stores work, their architecture, and why they become one of the most important components in extracting the full potential of distributed computing in order to carry out large-scale data operations.
Basics of Distributed Computing
What is Distributed Computing?
Think of distributed computing as a team sport. Just like a football team spreads out across the field, each player (or computer, in this case) has a specific role to play. This setup allows tasks to be handled simultaneously, speeding up processing and making the system more reliable. Instead of one giant supercomputer doing all the work, we have many smaller computers (called nodes) working together. This teamwork approach makes handling vast amounts of data more efficient and faster.
Key Concepts in Distributed Computing
Nodes: These are like individual team players. Each node is a separate computer responsible for a portion of the workload.
Clusters: Imagine a group of players forming a strategy. A cluster is a team of nodes working together closely to complete tasks more efficiently than they could individually.
Distributed File Systems: Think of this as the playbook shared among players. It ensures that all nodes can access the necessary data to perform their tasks, no matter where they are located.
MapReduce: This is a game plan for processing large sets of data. It involves breaking down the task into smaller chunks (Map) and then combining the results to solve a larger problem (Reduce).
NoSQL Databases: These are like specialized training techniques for players. They are designed to handle lots of different types of data quickly and without strict rules that traditional databases adhere to, making them perfect for diverse and rapidly changing data.
Real-Life Example of Distributed Computing
Consider a global delivery company that needs to track thousands of packages shipped across various routes daily. Distributed computing allows the company to use computers in different locations to handle local data about packages. This system ensures that data is processed near its source, speeding up the tracking process and making it more efficient.
Challenges in Distributed Computing
Scalability: As the team grows (more nodes), managing everyone becomes more complex. The system must handle this growth without slowing down or becoming inefficient.
Fault Tolerance: Sometimes, a player might get injured (node failure). The system needs to continue without interruption, automatically passing the injured player's tasks to others.
Consistency: All team members need to have up-to-date and consistent information. In distributed computing, ensuring that all nodes show the same data, even if they are updated at different times, can be tricky.
Latency: Communication delays between players (nodes) in different locations can affect gameplay. The system needs strategies to minimize these delays to maintain performance.
Dive into Large-Scale Data Stores
Apache Hive
Overview and Architecture
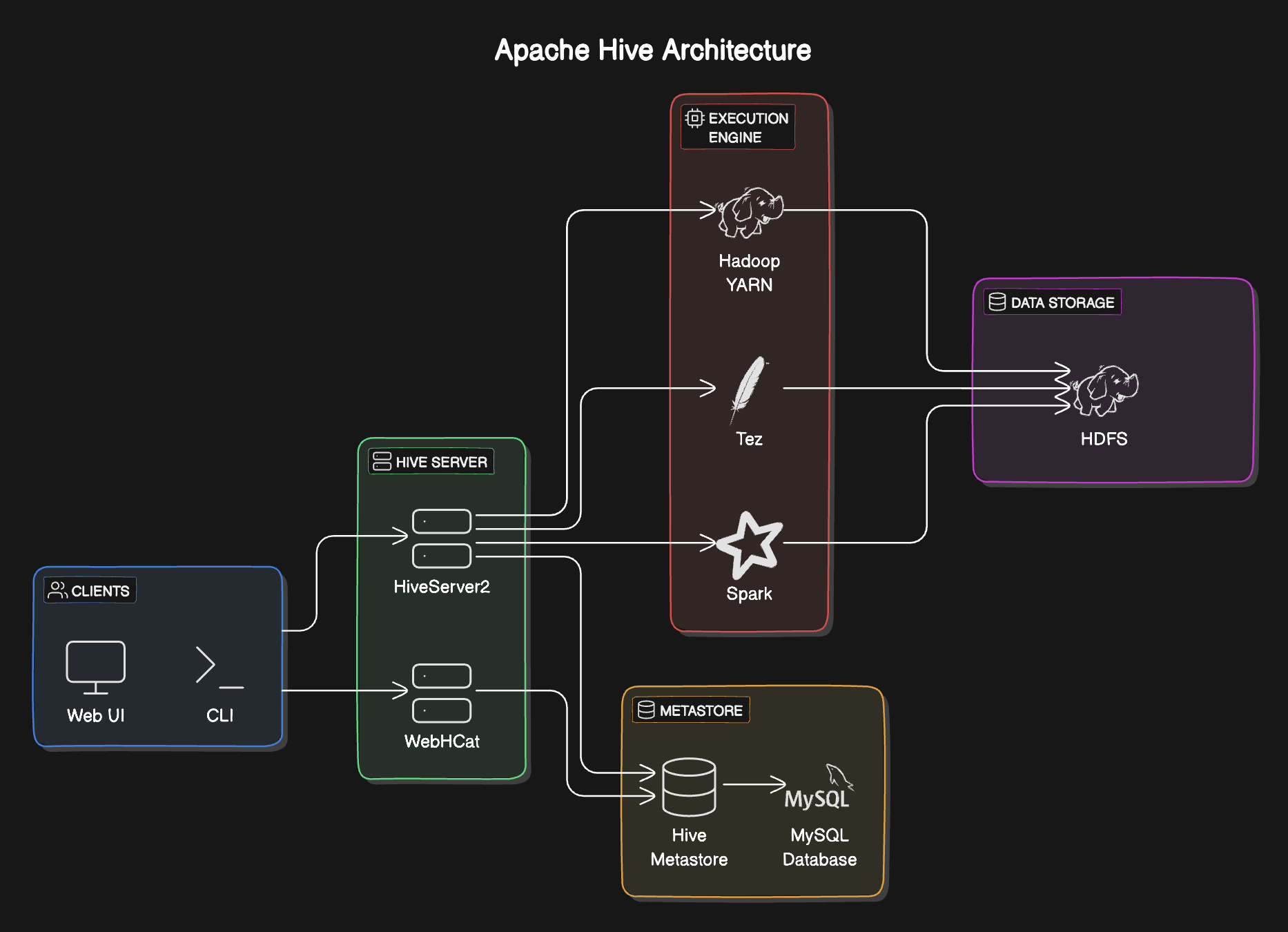
Apache Hive is like the brains of a data operation, designed to make sense of large volumes of data. Hive provides a SQL-like interface to query data stored in various databases and file systems that integrate with Hadoop. It's built on top of the Hadoop ecosystem and converts SQL queries into MapReduce jobs, making it an essential tool for data warehousing tasks.
How Hive Operates on Top of Hadoop
Think of Hadoop as the foundation of a building, while Hive is the upper structure that makes the space livable and functional. Hive uses Hadoop's Distributed File System (HDFS) to store its data and Hadoop's MapReduce to process the data. Hive's architecture allows users to interact with data in Hadoop using SQL, which is familiar to those who have used traditional relational databases, thereby simplifying the complexities of Hadoop.
Use Cases and Advantages
Use Cases: Ideal for data warehousing applications where large datasets are batch-processed and analyzed.
Advantages: Provides a familiar SQL interface, which reduces the learning curve for database professionals and allows complex transformations and analysis on big data.
Apache Cassandra
Overview and Architecture
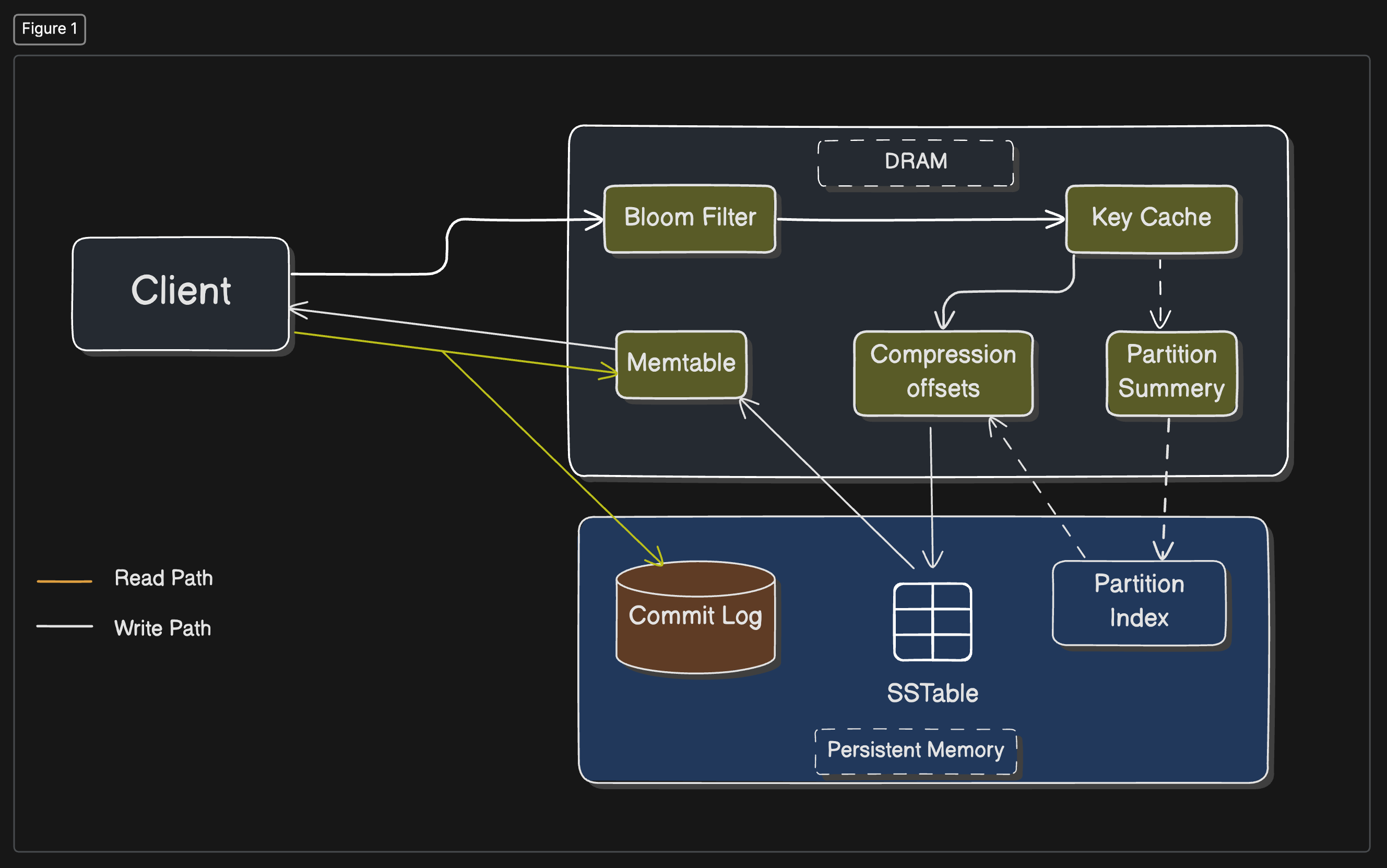
Apache Cassandra is like a warehouse designed for speed and scale. It's a highly scalable, high-performance distributed database designed to handle large amounts of data across many commodity servers without a single point of failure. Its architecture is a peer-to-peer distributed system where all nodes (servers) are the same; there's no master that could become a bottleneck or a single point of failure.
Key Features
Decentralized: Every node in the cluster has the same role, there is no master node, which helps in avoiding bottlenecks.
Replication and Multi-data Center Distribution: Cassandra is designed to replicate data automatically to multiple nodes and data centers, enhancing data availability and disaster recovery.
Use Cases and Advantages
Use Cases: Perfect for applications needing high availability and scalability, such as IoT, web data, and mobile apps.
Advantages: Provides robust support for clusters spanning multiple data centers, with asynchronous masterless replication allowing low latency operations for all clients.
Comparison with Other Data Stores
HBase vs. Cassandra
HBase: Optimized for read-heavy applications where access to large datasets is required rapidly. It's best for real-time querying of big data.
Cassandra: Better suited for write-heavy applications due to its efficient write performance and ability to handle very high write volumes.
MongoDB vs. Cassandra
MongoDB: Offers more flexible data storage with a document-oriented model, suitable for applications that need dynamic queries and need to handle a variety of data types.
Cassandra: Focuses on performance, linear scalability, and durability, making it better for applications requiring massive scalability and high reliability across multiple data centers.
When to Use Each
Data Store
Best for
Strengths
Typical Use Cases
Apache Hive
Complex, ad-hoc querying of big data
Familiar SQL interface, integrates well with Hadoop, good for batch processing
Data warehousing, business intelligence, large-scale analytics
Apache Cassandra
High write volumes, scalability
Horizontal scalability, no single point of failure, masterless architecture
Web and mobile apps, IoT, write-heavy applications
HBase
Real-time read/write access
Fast access to large datasets, scales horizontally, integrates with Hadoop
Real-time analytics, monitoring apps, where speed is critical
MongoDB
Dynamic queries and diverse data types
Flexible document model, dynamic schemas, robust indexing and querying capabilities
Catalogs, content management, applications with varied data
Core Technologies Behind These Data Stores
Data Partitioning (Sharding)
Data partitioning, commonly known as sharding, is like dividing a big task among your team members to complete it faster. In distributed data stores, sharding involves splitting large datasets into smaller, more manageable pieces, or 'shards', that can be distributed across multiple servers or nodes. This approach not only speeds up data retrieval by allowing operations to run concurrently across multiple shards but also enhances horizontal scaling, as shards can be spread across additional machines as data grows.
Replication Strategies
Replication is akin to keeping backup copies of your documents. In distributed databases, data is replicated across different nodes or servers to ensure high availability and fault tolerance. If one node fails, the system can automatically switch to a replica without any data loss or downtime. There are various replication strategies, such as:
Master-slave replication: One node is the 'master' that handles writes, while one or more 'slave' nodes handle reads and serve as backups.
Peer-to-peer replication: Each node can accept reads and writes, acting as both master and replica, which eliminates single points of failure.
Consistency Models
Imagine if everyone in your team had slightly different versions of the same document. Confusing, right? Consistency models in distributed systems ensure that all nodes show the same data at any given time, which can be challenging due to replication and the inherent latency of data distribution. The two primary models are:
Eventual Consistency: Updates to one node will propagate to all nodes eventually, ensuring that all replicas become consistent over time. This model allows for high availability and performance but at the cost of immediate consistency.
Strong Consistency: Every read receives the most recent write or an error. Although this model ensures that all users see the same data at the same time, it can compromise availability in the event of a node failure.
CAP Theorem Implications
The CAP Theorem is a fundamental principle that posits that a distributed system can only simultaneously guarantee two of the following three properties:
Consistency (C): Every read receives the most recent write or an error.
Availability (A): Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
Partition Tolerance (P): The system continues to operate despite an arbitrary number of messages being dropped (due to network failures).
In practice, while all systems aim for partition tolerance (since network failures are common), developers must choose between prioritizing consistency or availability, leading to different configurations based on specific application needs.
Real-World Applications and Case Studies
In this section, we will explore how large-scale data stores like Apache Hive and Apache Cassandra are used in real-world scenarios, examining the benefits and discussing how these technologies enhance scalability and performance.
Apache Hive in Action
Company Example: Facebook
Usage: Facebook uses Apache Hive for data warehousing, allowing them to analyze petabytes of data efficiently. Hive enables their analysts, who are already familiar with SQL, to run queries on massive datasets stored in Hadoop without needing to learn new programming paradigms.
Benefits: Hive facilitates easy data summarization, querying, and analysis of large volumes of data. It supports Facebook's data analysts in generating reports that influence product decisions and user experience strategies.
Apache Cassandra in Action
Company Example: Netflix
Usage: Netflix employs Apache Cassandra to handle its massive scale and real-time requirements, particularly for services like tracking watched history and bookmarks across millions of users worldwide.
Benefits: Cassandra's ability to handle thousands of write operations per second while maintaining operational simplicity and robustness is crucial for Netflix’s 24/7 uptime and quick data access demands.
Scalability and Performance Improvements
Scalability
Hive: As data grows, Hive scales horizontally by adding more machines to the Hadoop cluster. This scalability is crucial for companies like Facebook, where data volume and demand for faster processing grow continually.
Cassandra: Cassandra’s architecture is designed to scale linearly; doubling the number of nodes doubles the capacity without a significant increase in latency. This feature is particularly beneficial for services like Netflix, which experience massive and often unpredictable spikes in workload.
Performance Improvements
Hive: By converting SQL queries into MapReduce jobs, Hive optimizes the execution across multiple nodes, thereby utilizing the full power of the underlying Hadoop infrastructure. This results in efficient processing of large-scale data queries.
Cassandra: Cassandra's distributed nature allows it to process large volumes of writes very quickly. Its data distribution and replication strategies ensure minimal impact on performance even as the system scales.
Challenges and Best Practices in Managing Large-Scale Data Stores
Challenges
Complex Setup and Maintenance: Deploying and maintaining distributed data stores like Apache Hive and Cassandra involves intricate configuration and continuous optimization to handle varying data loads and ensure peak performance.
Data Consistency Issues: Achieving consistency across distributed nodes can be complex, particularly with systems that prioritize high availability and fault tolerance, such as Cassandra’s eventual consistency model.
Data Skew and Load Balancing: Data skew occurs when certain nodes handle more data or traffic than others, leading to potential performance bottlenecks. Balancing the load effectively across nodes is crucial for maintaining system efficiency.
Scalability Costs: While these databases scale horizontally, the infrastructure costs—both hardware and operational—can escalate quickly as data and throughput demands increase.
Best Practices
Effective Data Modeling: For Cassandra, it's crucial to model data based on the anticipated query patterns, which involves understanding partition keys and data distribution. In Hive, organizing data into efficient partitions and using bucketing can drastically improve query performance.
Proactive Monitoring: Employing robust monitoring tools to track performance metrics and system health can preemptively address issues before they impact operations. This includes monitoring disk usage, read/write latencies, and node health.
Regular Software Updates: Keeping the data store software up-to-date is vital to leverage new features, performance improvements, and security patches that enhance overall system robustness.
Load Testing: Conduct systematic load testing to simulate real-world usage patterns. This helps identify potential scalability issues and the system’s behavior under stress.
Conclusion
Large-scale data stores like Apache Hive and Apache Cassandra play an indispensable role in the ecosystem of distributed computing. They enable organizations to manage vast quantities of data efficiently, providing the scalability and flexibility required in today’s data-driven environment. As data volumes continue to grow exponentially, the ability to effectively deploy, manage, and leverage these technologies becomes a pivotal factor in an organization’s success.
By overcoming the inherent challenges and adhering to established best practices, companies can maximize the potential of their data infrastructure to drive innovation, enhance customer experiences, and make informed decisions that keep them competitive in a rapidly evolving digital landscape.
We at CreoWis believe in sharing knowledge publicly to help the developer community grow. Let’s collaborate, ideate, and craft passion to deliver awe-inspiring product experiences to the world.
This article is crafted by Arnab Chatterjee, a passionate developer at CreoWis. You can reach out to him on X/Twitter, LinkedIn, and follow his work on the GitHub.
Data at Scale: Unlocking the Secrets of Hive and Cassandra in Distributed Systems